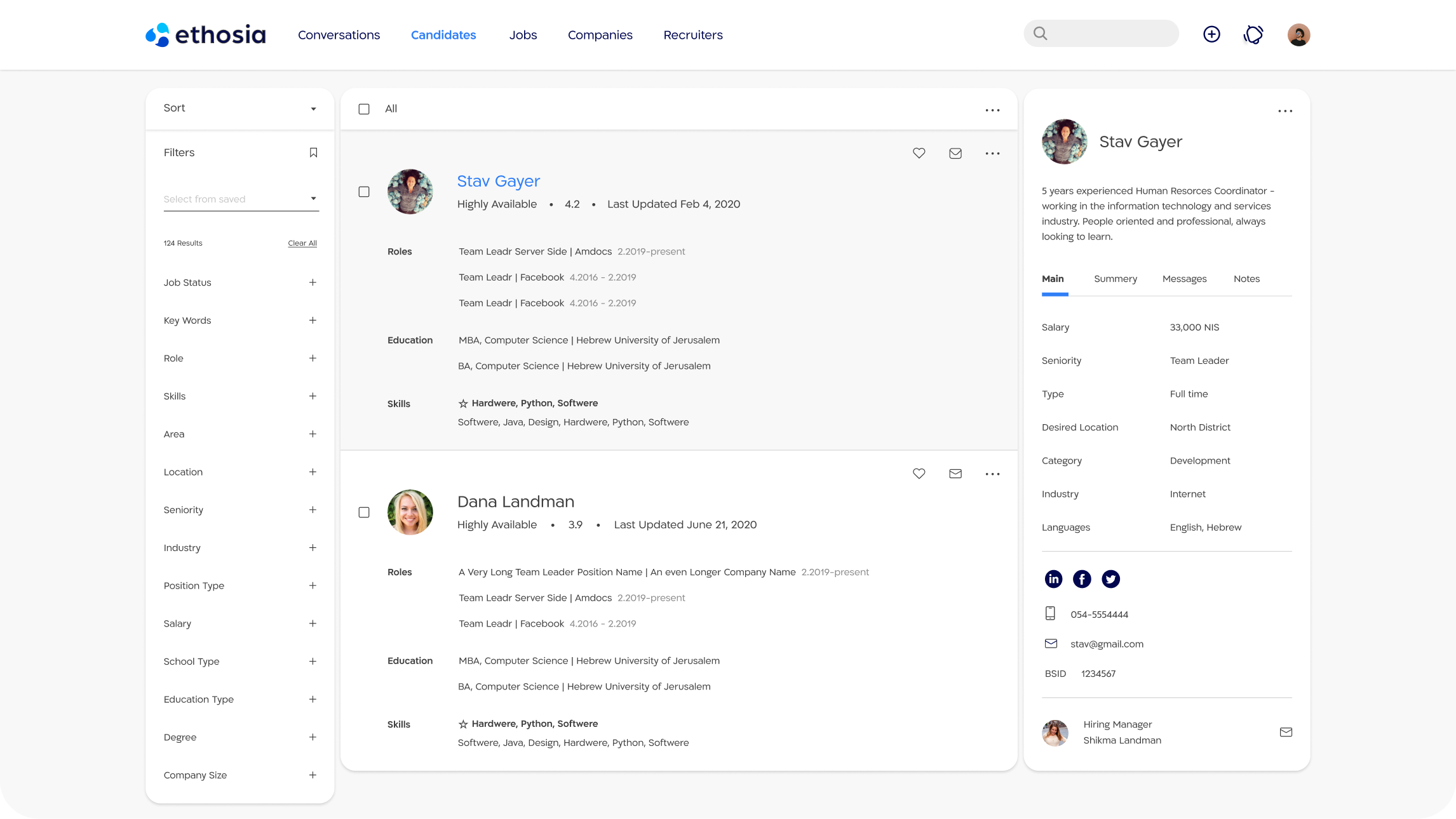
Develop, maintain and operate complex data pipelines that process and serve Petabytes.
Build tools to monitor and alert on data quality and availability.
Design and develop resilient and autonomous building blocks that expose the data to the rest of the company – from researches to the scalable automatic process which train machine learning models.
5+ years experience in backend development of distributed, scalable systems (micro-services) using one of Scala/Python/Java/Go.
5+ years of working experience in Linux.
Previous experience with leading at least one Data project end-to-end, from requirements to implementation.
4+ year experience in data engineering – data pipeline design, implementation, operations.
Experience working with NoSQL databases – at least one of Cassandra/HBase/Mongo/Couchbase/Redis/Presto.
Experience working with SQL databases – at least one of PostgreSQL/MySQL/Oracle.
Experience working with distributed workflow orchestrator – Cadence/Temporal.
Experience working with gRPC (including Protobuf).
Experience working with Prometheus/Graphana/Kibana.
Eager to learn new technologies and programming languages.
BSc. Computer Science